Làm sạch dữ liệu là cách để giảm thiểu những lỗi có thể xảy ra ở quá trình nhập liệu. Những câu lỗi sẽ được đưa vào tỉ lệ missing, tỉ lệ missing càng cao thì bảng dữ liệu càng thiếu sự thuyết phục.
Missing ta có thể hiểu là một số dữ liệu nào đó trong bảng số liệu của chúng ta bị lỗi, lỗi này có thể là khuyết thông tin, thông tin sai, hoặc không hợp logic.
Missing ta có thể hiểu là một số dữ liệu nào đó trong bảng số liệu của chúng ta bị lỗi, lỗi này có thể là khuyết thông tin, thông tin sai, hoặc không hợp logic.
Việc
missing dữ liệu rất nhiều nguyên nhân, và trong quy trình thực hiện 1
nghiên cứu, lỗi này sinh ra ngay trong khâu đầu tiên là thiết kế bảng
hỏi. Câu hỏi không rõ ràng, đáp án đưa ra lệch với đáp án thực tế, bước
nhảy chưa chuẩn. Tiếp đến là kỹ năng phỏng vấn của điều tra viên như
thiếu thông tin, hỏi sai ý, điền sai, chọn sai đối tượng phỏng vấn...
Hoặc do người trả lời không muốn trả lời, không muốn cung cấp thông tin,
nhất là đối với những vấn đề tế nhị. Khâu đọc soát bảng hỏi của điều
phối khảo sát chưa kỹ càng. Việc nhập liệu sai do lỗi đánh thừa chữ, sai
do việc chọn đáp án của điều tra viên không rõ ràng. Tỷ lệ missing
nhiều có thể khiến cho số liệu giảm đi tính thuyết phục
Cho
nên việc giảm đến mức tối thiểu tỷ lệ missing trong 1 bảng dữ liệu cần
phải được kiểm soát ngay từ khâu lập bảng hỏi, cho đến khi xử lý số
liệu.
Song tỷ lệ missing có thể được hạn chế phần nào nếu mã hoá và lọc thông tin tốt.
Quay lại phần mã hoá bảng hỏi ở trên.

 Đối
với những câu có gắn giá trị ở cột Values ví dụ như câu 3, giới tính:
1/nam, 2/nữ. Người mã hoá dự đoán rằng: sẽ có những trường hợp xảy ra
dẫn đến lỗi sai: như việc thay vì người nhập liệu đánh 1 hoặc 2, thì họ
đánh máy 11, 22. Đó là 1 lỗi phổ biến trong nhập liệu. Chuyển sang ô
Missing người mã hoá sẽ nhấp vào ô missing để đánh 2 lỗi này vào hệ
thống missing. như trên.
Đối
với những câu có gắn giá trị ở cột Values ví dụ như câu 3, giới tính:
1/nam, 2/nữ. Người mã hoá dự đoán rằng: sẽ có những trường hợp xảy ra
dẫn đến lỗi sai: như việc thay vì người nhập liệu đánh 1 hoặc 2, thì họ
đánh máy 11, 22. Đó là 1 lỗi phổ biến trong nhập liệu. Chuyển sang ô
Missing người mã hoá sẽ nhấp vào ô missing để đánh 2 lỗi này vào hệ
thống missing. như trên. Hoặc
bên cạnh đó có thể đưa ra cách phương án missing cho người nhập liệu
điền vào nếu bảng hỏi không rõ ràng. Ví dụ: 0 là những người không trả
lời, 8 hay 9 là người nhập liệu không chắc chắn nhập 1 nam hay 2 nữ khi
điều tra viên đánh dấu bảng hỏi không rõ ràng. Nhờ đó người nhập liệu sẽ
nhập những giá trị khuyết bằng những con số kể trên
Hoặc
bên cạnh đó có thể đưa ra cách phương án missing cho người nhập liệu
điền vào nếu bảng hỏi không rõ ràng. Ví dụ: 0 là những người không trả
lời, 8 hay 9 là người nhập liệu không chắc chắn nhập 1 nam hay 2 nữ khi
điều tra viên đánh dấu bảng hỏi không rõ ràng. Nhờ đó người nhập liệu sẽ
nhập những giá trị khuyết bằng những con số kể trênCác cách để làm sạch dữ liệu:
Thứ
nhất là dùng bảng tần số để phát hiện số liệu lạ, dùng lênh Frequency
(xem bài trước). Ví dụ: tôi cố ý sửa bảng số liệu thống kê cuộc tổng
điều tra Mỹ (ví dụ có sẵn trong SPSS 11.5) có hai lỗi missing. Frequency
ra như sau:
Statistics
|
||
Respondent's
Sex
|
||
N
|
Valid
|
1515
|
Missing
|
2
|
|
Respondent's Sex
|
|||||
Frequency
|
Percent
|
Valid Percent
|
Cumulative Percent
|
||
Valid
|
Male
|
636
|
41.9
|
42.0
|
42.0
|
Female
|
879
|
57.9
|
58.0
|
100.0
|
|
Total
|
1515
|
99.9
|
100.0
|
||
Missing
|
11
|
1
|
.1
|
||
22
|
1
|
.1
|
|||
Total
|
2
|
.1
|
|||
Total
|
1517
|
100.0
|
|||

Missing nhận những giá trị lạ như 11, 22. Ta tiến hành tìm kiếm lỗi sai đó để sửa lại.
Ta vào Edit, chọn find, hoặc bấm tổ hợp phím Ctrl F. Sẽ ra giao diện như sau:
Ta đánh những giá trị lạ (ví dụ 11) vào và bấm Find
next. Hệ thống sẽ bôi đen một trong số những ô sai nhờ đó ta dễ dàng
sửa lại. Tiếp tục Ctrl F để tìm tiếp, khi không tìm thấy ô có số 11,
tiếp tục tìm kiếm với số 22. Tìm kiếm những giá trị lạ khác (ngoài 2 đáp
án đã mã hoá) nếu có.
Ta vào Edit, chọn find, hoặc bấm tổ hợp phím Ctrl F. Sẽ ra giao diện như sau:
 |
| Tìm dữ liệu lỗi bằng Find Next |
Tiếp theo là dùng Sort Case để tìm những lỗi đơn giản nằm ngoài đáp án.
Ví dụ với câu đánh giá mức độ hạnh phúc của người trả lời (trích tổng điều tra Mỹ SPSS11.5)
 |
| Tìm dữ liệu lỗi bằng Sort Cases |
Câu hỏi có 3 lựa chọn 1/rất hạnh phúc, 2/khá hạnh phúc, 3/không quá hạnh phúc. Như vậy ta sẽ dụng Sort Case để tìm ra những câu nhận những giá trị lớn hơn 3 và nhỏ hơn 1. Thì đó là những giá trị sai.
Vào Data. Chọn Sort Cases
Giao diện hiện ra như sau:


Có thể tìm ra lỗi sai còn việc sửa lỗi sai như thế nào hay xoá những phiếu có lỗi sai đi là tuỳ thuộc vào người xử lý.
Tìm lỗi sai logic bằng bảng kết hợp đa biến:
 |
| Tìm lỗi sai bằng bảng kết hợp đa biến |

Đưa tuổi vào rown, số con vào columm. Bấm OK ta được bảng sau:
Number of Children (số con)
|
||||||||||
| 0 |
1
|
2
|
3
|
4
|
5
|
6
|
7
|
Eight or More
|
||
Age of
Respondent
(Độ tuổi)
|
15
|
1
|
||||||||
| 18 |
2
|
1
|
||||||||
| 19 |
6
|
1
|
2
|
|||||||
| 20 |
11
|
7
|
||||||||
| 21 |
33
|
5
|
||||||||
| 22 |
26
|
3
|
4
|
1
|
1
|
|||||
| 23 |
18
|
7
|
2
|
|||||||
| 24 |
12
|
6
|
4
|
2
|
||||||
| 25 |
20
|
4
|
1
|
3
|
||||||
Trên hình cho thấy có một người 15 tuổi, nhưng có 3 con. Điều này giả sử là vô lý.
Hay có những tình huống vô lý như 1 người 15 tuổi mà học vấn tiến sỹ.
Sau đó ta sẽ dùng lệnh select cases để xem lỗi sai này

Vào
Data, chọn Select Case, chon If. Giao diện hiện ra, đưa
tuổi=15&số con =3. Continue => OK. Chương trình sẽ gạch
chéo hết những ô không phải đúng với điều kiện trên.

Đồng
thời sẽ xuất hiện 1 câu khác ở phía cuối (kéo thanh ngang chạy về cuối)
có tên là filter_$. Những câu không thoả mãn với điều kiện (tuổi=15 và
con=3) và bị gạch chéo sẽ nhận giá trị 0. Còn những câu thoả mãn với
điều kiện nhận giá trị 1. Như vậy những câu nhận giá trị 1 là câu có
lỗi.
Để tìm ra những câu nhận giá trị trong hơn một ngàn bảng hỏi rất dễ. Chỉ cần Ctrl F

Nhập giá trị là 1 rồi Find next, ta sẽ thấy những câu sai bị bôi đen như sau:
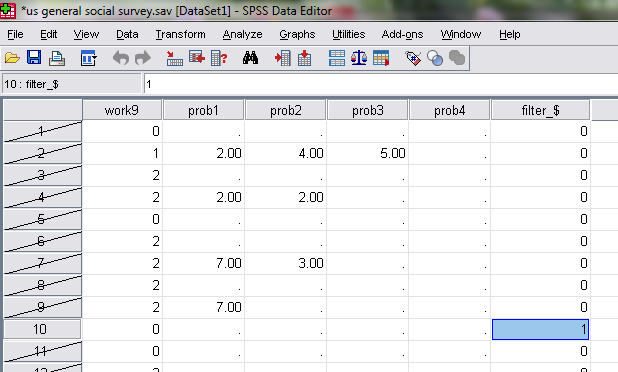
Bạn có thể sửa chúng (bằng cách nào đó) thì có thể dễ dàng.
Còn tôi sẽ bỏ những câu lỗi (những câu nhận giá trị 1) đi. Lúc này tôi sẽ thực hiện thêm 1 lệnh Select Cases nữa.
 |
| Lọc lỗi sai bằng Select Cases |
Trong
lệnh này, tôi sẽ cho câu mới (biến mới được tạo ra) là Filter_$=0. Tức
là chỉ nhận câu không đủ điều kiện (tuổi=15, số con=3). Continue
=> OK
Và kết quả của tôi là:

Hệ thống đã gạch đi câu sai logic.
Phần trình bày đến đây đã đủ dài. Xin được tiếp tục chia sẻ với bạn đọc ở bài sau.
Không có nhận xét nào:
Đăng nhận xét